ORM API¶
模型¶
模型字段定义为模型本身的属性::
from odoo import models, fields
class AModel(models.Model):
_name = 'a.model.name'
field1 = fields.Char()
警告
这意味着您不能定义同名的字段和方法,后者将静默覆盖前者。
默认情况下,字段的标签(用户可见名称)是字段名称的大写版本,可以通过 string 参数覆盖。::
field2 = fields.Integer(string="Field Label")
有关字段类型和参数的列表,请参阅 字段参考 。
默认值定义为字段的参数,可以是一个值::
name = fields.Char(default="a value")
或者作为一个计算默认值的函数,该函数应返回该值::
def _default_name(self):
return self.get_value()
name = fields.Char(default=lambda self: self._default_name())
API
- class odoo.models.BaseModel[源代码]¶
Odoo 模型的基类。
Odoo 模型通过继承以下之一创建:
Model用于常规的数据库持久化模型TransientModel用于临时数据,存储在数据库中但会定期自动清理AbstractModel用于抽象超类,旨在由多个继承模型共享。
系统会为每个数据库自动实例化每个模型一次。这些实例表示每个数据库上可用的模型,并取决于该数据库上安装了哪些模块。每个实例的实际类是由创建和继承相应模型的 Python 类构建的。
每个模型实例都是一个“记录集”,即模型记录的有序集合。记录集由诸如
browse()、search()或字段访问等方法返回。记录没有显式表示:一条记录被表示为包含单条记录的记录集。要创建不应被实例化的类,可以将
_register属性设置为 False。- _auto: bool = False¶
是否应创建数据库表。如果设置为
False,则需要重写init()方法以创建数据库表。对于抽象模型,自动默认为
True。小技巧
要创建不带任何表的模型,请继承
AbstractModel。
- _inherits: frozendict[str, str] = {}¶
字典 { ‘父模型’ : ‘多对一字段’ },将父业务对象的 _name 映射到相应的外键字段名称以供使用:
_inherits = { 'a.model': 'a_field_id', 'b.model': 'b_field_id' }
实现基于组合的继承:新模型暴露所有继承模型的字段,但不会存储其中任何一个:这些值本身仍然存储在关联的记录中。
警告
如果在
_inherits的模型中定义了多个同名字段,则继承的字段将对应于最后一个(按 inherits 列表顺序)。
- _check_company_auto: bool = False¶
在写入和创建时,调用
_check_company以确保具有check_company=True属性的关系字段的公司一致性。
- _parent_store: bool = False¶
设置为 True 以计算 parent_path 字段。
与
parent_path字段一起,设置记录树结构的索引存储,以便通过child_of和parent_of域运算符对当前模型的记录执行更快的分层查询。
抽象模型¶
- odoo.models.AbstractModel[源代码]¶
alias of
odoo.orm.models.BaseModel
模型¶
- class odoo.models.Model(env: Environment, ids: tuple[IdType, ...], prefetch_ids: Reversible[IdType])[源代码]¶
常规数据库持久化 Odoo 模型的主要超类。
Odoo 模型通过继承此类创建:
class ResUsers(Model): ...
系统稍后会在每个数据库(安装了该类模块的数据库)上实例化一次该类。
- _auto: bool = True¶
是否应创建数据库表。如果设置为
False,则需要重写init()方法以创建数据库表。对于抽象模型,自动默认为
True。小技巧
要创建不带任何表的模型,请继承
AbstractModel。
- _abstract: typing.Literal[False] = False¶
模型是否为 抽象 。
临时模型¶
- class odoo.models.TransientModel(env: Environment, ids: tuple[IdType, ...], prefetch_ids: Reversible[IdType])[源代码]¶
临时记录的模型超类,旨在暂时持久化,并定期清理。
TransientModel 的访问权限管理较为简化,所有用户都可以创建新记录,但只能访问自己创建的记录。超级用户对所有 TransientModel 记录拥有无限制的访问权限。
- _transient_max_count = 0¶
临时记录的最大数量,如果为
0则无限制
- _transient_max_hours = 1.0¶
最大空闲生存时间(以小时为单位),如果为
0则无限制
- _transient_vacuum()[源代码]¶
清理临时记录。
当达到
_transient_max_count或_transient_max_hours条件(如果有)时,此操作会从临时模型表中删除旧记录。实际清理只会每 5 分钟发生一次。这意味着此方法可以频繁调用(例如,每当创建新记录时)。
同时启用 max_hours 和 max_count 的示例:
假设 max_hours = 0.2(即 12 分钟),max_count = 20,表中有 55 行数据,其中 10 行是在过去 5 分钟内创建/修改的,另有 12 行是在 5 至 10 分钟前创建/修改的,其余的则是在 12 分钟前创建/修改的。
基于时间的清理将保留过去 12 分钟内创建/修改的 22 行数据
基于数量的清理将删除另外 12 行数据。不仅仅是 2 行,否则每次添加都会立即再次达到上限。
过去 5 分钟内创建/修改的 10 行数据将不会被删除
字段¶
- class odoo.fields.Field[源代码]¶
字段描述符包含字段定义,并管理记录上对应字段的访问和赋值。实例化字段时可以提供以下属性:
- 参数
string (str) – 用户看到的字段标签;如果未设置,ORM 将使用类中的字段名称(首字母大写)。
help (str) – 用户看到的字段提示信息
readonly (bool) – 字段是否为只读(默认值:
False)。这只会影响 UI。代码中的任何字段赋值都有效(如果字段是存储字段或可逆字段)。required (bool) – 字段值是否为必填项(默认值:
False)index (str) – 字段是否在数据库中建立索引,以及索引的类型。注意:这对非存储字段和虚拟字段无效。可能的值包括: *
"btree"或True:标准索引,适用于 many2one 字段 *"btree_not_null":不包含 NULL 值的 BTREE 索引(当大多数值为 NULL 或从不搜索 NULL 时有用) *"trigram":使用三元组的广义倒排索引(GIN,适用于全文搜索) *None或False:无索引(默认值)default (value or callable) – 字段的默认值;可以是一个静态值,也可以是一个接受记录集并返回值的函数;使用
default=None来丢弃字段的默认值groups (str) – 逗号分隔的组 XML ID 列表(字符串);此设置将字段访问限制为仅限指定组的用户
company_dependent (bool) – 字段值是否依赖于当前公司;值以 JSONB 字典的形式存储在模型表中,键为公司 ID。模型 ir.default 中存储的字段默认值将用作 JSONB 字典中未指定值的回退值。
copy (bool) – 记录复制时是否应复制字段值(默认值:普通字段为
True,one2many和计算字段(包括属性字段和关联字段)为False)store (bool) – whether the field is stored in database (default:
True,Falsefor computed fields)default_export_compatible (bool) – 字段是否必须在兼容导入的导出中默认导出
search (str) – 实现字段搜索的方法名称。该方法接受一个操作符和值。在调用此函数之前会运行基本的域优化。例如,所有
'='都被转换为'in',布尔字段的条件被设置为操作符为'in'/'not in'且值为[True]。如果该方法不支持该操作符,应return NotImplemented。在这种情况下,ORM 可以尝试使用其他语义等效的操作符调用它。例如,如果未实现相应的负操作符,则尝试使用正操作符。该方法必须返回一个 搜索域 ,用于替换其域中的(field, operator, value)。请注意,存储字段实际上可以有一个搜索方法。搜索方法将被调用来重写条件。例如,这对于清理条件中使用的值可能很有用。 .. code-block:: python def _search_partner_ref(self, operator, value): if operator not in (‘in’, ‘like’): return NotImplemented … # 在此添加您的逻辑,示例 return Domain(‘partner_id.ref’, operator, value)
聚合
- 参数
aggregator (str) – 使用“分组依据”功能时,webclient 在此字段上使用的默认聚合函数。支持的聚合器有: *
count:行数 *count_distinct:不同行数 *bool_and:如果所有值都为 true,则为 true,否则为 false *bool_or:如果至少一个值为 true,则为 true,否则为 false *max:所有值的最大值 *min:所有值的最小值 *avg:所有值的平均值(算术平均值) *sum:所有值的总和group_expand (str) – 在 kanban/列表/甘特图视图中对当前字段进行分组时用于扩展结果的函数。对于选择字段,
group_expand=True会自动扩展所有选择键的分组。 .. code-block:: python @api.model def _read_group_selection_field(self, values, domain): return [‘choice1’, ‘choice2’, …] # 可用的选择选项。 @api.model def _read_group_many2one_field(self, records, domain): return records + self.search([custom_domain])
计算字段
- 参数
precompute (bool) – 是否应在数据库记录插入之前计算字段。当字段可以在记录插入之前计算时,应手动将某些字段指定为 precompute=True。(例如,避免基于 search/_read_group 的统计字段),链接到前一条记录的 many2one,…(默认:
False) .. warning:: 仅当未向 create() 提供显式值和默认值时才会进行预计算。这意味着默认值会禁用预计算,即使字段被指定为 precompute=True。 如果给定模型的记录不是批量创建的,预计算字段可能会适得其反。考虑逐个创建许多记录的情况。如果字段未预计算,通常会在 flush() 时批量计算,并且预取机制将有助于使计算高效。另一方面,如果字段是预计算的,计算将逐个进行,因此无法利用预取机制。 根据上述说明,预计算字段在 one2many 的行上可能很有意义,这些行通常由 ORM 本身批量创建,前提是它们是通过写入包含它们的记录来创建的。compute_sudo (bool) – 字段是否应以超级用户身份重新计算以绕过访问权限(默认情况下,存储字段为
True,非存储字段为False)recursive (bool) – 字段是否有递归依赖关系(字段
X具有类似parent_id.X的依赖关系);声明字段的递归性必须明确,以确保重新计算的正确性inverse (str) – 用于反向字段的方法名称(可选)
基本字段¶
- class odoo.fields.Char[源代码]¶
基本字符串字段,可以限制长度,通常在客户端显示为单行字符串。
- 参数
size (int) – 该字段存储值的最大大小
trim (bool) – 指示值是否被修剪(默认情况下为
True)。请注意,修剪操作由服务器代码和 Web 客户端同时应用,这确保了导入数据和 UI 输入数据之间的一致性行为。 - Web 客户端在 UI 中的写入/创建流程中修剪用户输入。 - 服务器在导入期间(在base_import中)修剪值,以避免修剪后的表单输入与存储的数据库值之间的差异。translate (bool or callable) – 启用字段值的翻译;使用
translate=True来整体翻译字段值;translate也可以是一个可调用对象,例如translate(callback, value)使用callback(term)来检索术语的翻译。
- class odoo.fields.Float[源代码]¶
封装了一个
浮点数。精度位数由(optional)``digits`` 属性指定。
当浮点数是与计量单位相关联的量时,重要的是使用正确的工具以适当的精度比较或舍入值。
Float 类为此提供了一些静态方法:
round()按给定精度舍入浮点数。is_zero()检查浮点数在给定精度下是否等于零。compare()按给定精度比较两个浮点数。示例
按计量单位的精度舍入数量::
fields.Float.round(self.product_uom_qty, precision_rounding=self.product_uom_id.rounding)
按计量单位的精度检查数量是否为零::
fields.Float.is_zero(self.product_uom_qty, precision_rounding=self.product_uom_id.rounding)
比较两个数量::
field.Float.compare(self.product_uom_qty, self.qty_done, precision_rounding=self.product_uom_id.rounding)
出于历史原因,compare 辅助函数使用 __cmp__ 语义,因此正确且惯用的使用方式如下:
如果 result == 0,则第一个和第二个浮点数相等;如果 result < 0,则第一个浮点数小于第二个;如果 result > 0,则第一个浮点数大于第二个。
高级字段¶
- class odoo.fields.Binary[源代码]¶
封装二进制内容(例如文件)。
- 参数
attachment (bool) – 字段是否应存储为
ir_attachment或模型表中的列(默认值:True)。
- class odoo.fields.Html[源代码]¶
封装 HTML 代码内容。
- 参数
sanitize (bool) – 值是否必须进行清理(默认值:
True)sanitize_overridable (bool) – 是否允许属于
base.group_sanitize_override组的用户绕过清理(默认值:False)sanitize_tags (bool) – 是否清理标签(仅接受白名单中的属性,默认值:
True)sanitize_attributes (bool) – 是否清理属性(仅接受白名单中的属性,默认值:
True)sanitize_style (bool) – 是否清理样式属性(默认值:
False)sanitize_conditional_comments (bool) – 是否移除条件注释(默认值:
True)sanitize_output_method (bool) – 是否使用 HTML 或 XHTML 进行清理(默认值:
html)strip_style (bool) – 是否移除样式属性(移除后不会被清理,默认值:
False)strip_classes (bool) – 是否移除类属性(默认值:
False)
- class odoo.fields.Image[源代码]¶
封装图像,扩展
Binary。如果图像尺寸超过
max_width/max_height的像素限制,图像将按比例调整大小至限制范围内。- 参数
注解
如果没有指定
max_width/max_height``(或设置为 0),且 ``verify_resolution为 False,则字段内容将完全不被验证,此时应使用Binary字段。
- class odoo.fields.Selection[源代码]¶
封装在不同值之间的独占选择。
- 参数
selection (list(tuple(str,str)) or callable or str) – 指定此字段的可能值。可以是一个
(value, label)对的列表,或者是一个模型方法或方法名称。selection_add (list(tuple(str,str))) – 在覆盖字段的情况下提供选择的扩展。它是一个
(value, label)对或单例(value,)的列表,其中单例值必须出现在被覆盖的选择中。新值会以与被覆盖选择和此列表一致的顺序插入:selection = [(‘a’, ‘A’), (‘b’, ‘B’)],selection_add = [(‘c’, ‘C’), (‘b’,)],结果为 [(‘a’, ‘A’), (‘c’, ‘C’), (‘b’, ‘B’)]。ondelete – 为任何带有 selection_add 的重写字段提供回退机制。它是一个字典,将 selection_add 中的每个选项映射到一个回退操作。此回退操作将应用于所有其 selection_add 选项映射到它的记录。操作可以是以下之一: - ‘set null’ – 默认值,所有具有此选项的记录将其选择值设置为 False。 - ‘cascade’ – 所有具有此选项的记录将与该选项一起被删除。 - ‘set default’ – 所有具有此选项的记录将被设置为字段定义的默认值。 - ‘set VALUE’ – 所有具有此选项的记录将被设置为给定值。 - <callable> – 一个可调用对象,其第一个且唯一的参数将是包含指定 Selection 选项的记录集,用于自定义处理。
属性
selection是必填的,除非是related或扩展字段的情况。
日期(时间)字段¶
日期 和 日期时间 是任何业务应用程序中非常重要的字段。它们的误用可能会导致隐性但令人头痛的错误,本节旨在为 Odoo 开发人员提供避免误用这些字段所需的知识。
为日期/日期时间字段赋值时,以下选项是有效的:
date或datetime对象。符合服务器格式的字符串:
False或None。
日期和日期时间字段类提供了辅助方法,以尝试转换为兼容类型:
to_date()将转换为datetime.dateto_datetime()将转换为datetime.datetime。
Example
解析来自外部源的日期/时间::
fields.Date.to_date(self._context.get('date_from'))
日期/日期时间比较的最佳实践:
日期字段只能与日期对象进行比较。
日期时间字段只能与日期时间对象进行比较。
警告
表示日期和日期时间的字符串可以在彼此之间进行比较,但结果可能不是预期的结果,因为日期时间字符串始终大于日期字符串,因此强烈不建议这样做。
对日期和日期时间的常见操作(如加法、减法或获取时间段的起点/终点)通过 Date 和 Datetime 提供。这些辅助工具也可以通过导入 odoo.tools.date_utils 来使用。
注解
时区
日期时间字段在数据库中存储为 无时区的时间戳 列,并以 UTC 时区存储。这是设计上的选择,因为它使 Odoo 数据库独立于托管服务器系统的时区。时区转换完全由客户端管理。
- class odoo.fields.Date[源代码]¶
封装了一个 Python
date对象。- static today(*args) datetime.date[源代码]¶
以 ORM 期望的格式返回当前日期。
注解
此函数可用于计算默认值。
- static context_today(record: BaseModel, timestamp: date | datetime | None = None) date[源代码]¶
以适合日期字段的格式返回客户端时区中的当前日期。
注解
此方法可用于计算默认值。
- 参数
record – 用于获取时区的记录集。
timestamp – 可选的 datetime 值,用于替代当前日期和时间(必须是 datetime 类型,普通日期无法在时区之间转换)。
- static to_date(value) datetime.date | None[源代码]¶
尝试将
value转换为date对象。警告
如果给定的值是 datetime 对象,它将被转换为 date 对象,并且所有与 datetime 相关的信息(如小时、分钟、秒、时区等)都将丢失。
- 参数
value (str or date or datetime) – 要转换的值。
- 返回
表示
value的对象。
- static to_string(value: Union[datetime.date, Literal[False]]) Union[str, Literal[False]][源代码]¶
将
date或datetime对象转换为字符串。- 参数
value – 要转换的值。
- 返回
以服务器日期格式表示
value的字符串,如果value是datetime类型,则小时、分钟、秒和时区信息将被截断。
- static start_of(value: D, granularity: Granularity) D[源代码]¶
从日期或时间获取时间段的起始时间。
- 参数
value – 初始日期或时间。
granularity – 时间段类型(字符串),可以是年、季度、月、周、日或小时。
- 返回
对应于指定时间段起始时间的日期/时间对象。
- static end_of(value: D, granularity: Granularity) D[源代码]¶
从日期或时间获取时间段的结束时间。
- 参数
value – 初始日期或时间。
granularity – 时间段类型(字符串),可以是年、季度、月、周、日或小时。
- 返回
对应于指定时间段起始时间的日期/时间对象。
- class odoo.fields.Datetime[源代码]¶
封装一个 Python
datetime对象。- static now(*args) datetime.datetime[源代码]¶
以 ORM 期望的格式返回当前日期和时间。
注解
此函数可用于计算默认值。
- static today(*args) datetime.datetime[源代码]¶
返回当前日期的午夜时间(00:00:00)。
- static context_timestamp(record: BaseModel, timestamp: datetime) datetime[源代码]¶
将给定的时间戳转换为客户端的时区时间。
注解
此方法*不*适用于默认初始化器,因为 datetime 字段在客户端显示时会自动转换。对于默认值,应使用
now()方法。- 参数
record – 用于获取时区的记录集。
timestamp (datetime) – 天真的 datetime 值(以 UTC 表示),将被转换为客户端时区时间。
- 返回
时间戳已转换为上下文时区中的带时区感知的 datetime。
- 返回类型
datetime
- static to_datetime(value) datetime.datetime | None[源代码]¶
将 ORM 中的
value转换为datetime值。- 参数
value (str or date or datetime) – 要转换的值。
- 返回
表示
value的对象。
- static to_string(value: Union[datetime.datetime, Literal[False]]) Union[str, Literal[False]][源代码]¶
将
datetime或date对象转换为字符串。- 参数
value (datetime or date) – 要转换的值。
- 返回
以服务器 datetime 格式表示
value的字符串,如果value是date类型,则时间部分将是午夜(00:00:00)。
- static start_of(value: D, granularity: Granularity) D[源代码]¶
从日期或时间获取时间段的起始时间。
- 参数
value – 初始日期或时间。
granularity – 时间段类型(字符串),可以是年、季度、月、周、日或小时。
- 返回
对应于指定时间段起始时间的日期/时间对象。
- static end_of(value: D, granularity: Granularity) D[源代码]¶
从日期或时间获取时间段的结束时间。
- 参数
value – 初始日期或时间。
granularity – 时间段类型(字符串),可以是年、季度、月、周、日或小时。
- 返回
对应于指定时间段起始时间的日期/时间对象。
关系字段¶
- class odoo.fields.Many2one[源代码]¶
此类字段的值是一个大小为 0(无记录)或 1(单条记录)的记录集。
- 参数
comodel_name (str) – 目标模型的名称,
必填,除非是相关字段或扩展字段。domain – 客户端候选值的可选域(域或一个将被评估以提供域的 Python 表达式)。
context (dict) – 处理该字段时在客户端使用的可选上下文。
ondelete (str) – 当引用的记录被删除时的操作;可能的值为:
'set null'、'restrict'、'cascade'。bypass_search_access (bool) – 是否绕过 comodel 上的访问权限(默认:
False)delegate (bool) – 将其设置为
True以使目标模型的字段可以从当前模型访问(对应于_inherits)。check_company (bool) – 标记该字段以在
_check_company()中进行验证。根据字段是否为 company_dependent,行为有所不同。对非 company_dependent 字段的约束是:目标记录的 company_id 必须与记录的 company_id 兼容。对 company_dependent 字段的约束是:目标记录的 company_id 必须与当前活动公司兼容。
- class odoo.fields.One2many[源代码]¶
One2many 字段;该字段的值是所有满足
comodel_name中inverse_name等于当前记录的记录集。- 参数
属性
comodel_name和inverse_name是必填的,除非是相关字段或字段扩展的情况。
- class odoo.fields.Many2many[源代码]¶
Many2many 字段;该字段的值是记录集。
- 参数
属性
relation、column1和column2是可选的。如果未提供,则会根据模型名称自动生成名称,前提是model_name和comodel_name不同!请注意,ORM 不允许在同一模型上具有相同 comodel 的多个隐式关系参数字段,因为这些字段将使用相同的表。ORM 防止两个 many2many 字段使用相同的关系参数,除非
两个字段使用相同的模型、comodel,并且关系参数是显式的;或者
至少有一个字段属于
_auto = False的模型。
- 参数
domain – 客户端候选值的可选域(域或一个将被评估以提供域的 Python 表达式)。
context (dict) – 处理该字段时在客户端使用的可选上下文。
check_company (bool) – 标记该字段以在
_check_company()中进行验证。根据字段属性添加默认的公司域。
- class odoo.fields.Command[源代码]¶
One2many和Many2many字段需要特殊的命令来操作它们实现的关系。在内部,每个命令都是一个 3 元素元组,其中第一个元素是标识命令的必需整数,第二个元素是要应用命令的相关记录 id(命令 update、delete、unlink 和 link)或 0(命令 create、clear 和 set),第三个元素是要写入记录的
values(命令 create 和 update)或相关记录的新ids列表(命令 set)或 0(命令 delete、unlink、link 和 clear)。这个三元组别名为CommandValue。通过 Python,我们鼓励开发者通过此命名空间的各种函数创建新命令。我们也鼓励开发者在比较现有命令的第一个元素时使用命令标识符常量名称。
通过 RPC,无法使用函数或命令常量名称。必须改写为一个包含三个元素的元组,其中第一个元素是命令的整数标识符。
- CREATE = 0¶
- UPDATE = 1¶
- DELETE = 2¶
- UNLINK = 3¶
- LINK = 4¶
- CLEAR = 5¶
- SET = 6¶
- classmethod create(values: ValuesType) CommandValue[源代码]¶
使用
values在关联模型中创建新记录,并将创建的记录与self关联。在
Many2many关系的情况下,在关联模型中会创建一条唯一的新记录,使得self中的所有记录都与该新记录关联。在
One2many关系的情况下,关联模型中会为self中的每条记录创建一条新记录,使得self中的每条记录恰好与一条新记录关联。返回命令三元组
(CREATE, 0, {values})
- classmethod update(id: int, values: ValuesType) CommandValue[源代码]¶
在关联记录上写入
values。返回命令三元组
(UPDATE, {id}, {values})
- classmethod delete(id: int) CommandValue[源代码]¶
从数据库中删除关联记录,并解除其与
self的关系。在
Many2many关系的情况下,如果记录仍与其他记录关联,则可能无法从数据库中删除该记录。返回命令三元组
(DELETE, {id}, 0)
- classmethod unlink(id: int) CommandValue[源代码]¶
移除
self与关联记录之间的关系。在
One2many关系的情况下,如果反向字段设置为ondelete='cascade',则给定记录将从数据库中删除。否则,反向字段的值将被设置为 False,并保留记录。返回命令三元组
(UNLINK, {id}, 0)
伪关系字段¶
计算字段¶
字段可以通过 compute 参数进行计算(而不是直接从数据库读取)。它必须将计算值赋给字段 。如果它使用了其他 字段 的值,则应使用 depends() 指定这些字段。::
from odoo import api
total = fields.Float(compute='_compute_total')
@api.depends('value', 'tax')
def _compute_total(self):
for record in self:
record.total = record.value + record.value * record.tax
当使用子字段时,依赖项可以是带点的路径::
@api.depends('line_ids.value') def _compute_total(self): for record in self: record.total = sum(line.value for line in record.line_ids)
计算字段默认不存储,它们在请求时计算并返回。设置
store=True会将它们存储在数据库中并自动启用搜索和分组。请注意,默认情况下,字段上设置了compute_sudo=True。通过对计算字段设置
search参数,也可以启用搜索功能。其值是一个返回 搜索域 的方法名称。::upper_name = field.Char(compute='_compute_upper', search='_search_upper') def _search_upper(self, operator, value): if operator == 'like': operator = 'ilike' return Domain('name', operator, value)
计算字段默认是只读的。要允许在计算字段上 设置 值,请使用
inverse参数。它是一个反转计算并设置相关字段的函数名称:document = fields.Char(compute='_get_document', inverse='_set_document') def _get_document(self): for record in self: with open(record.get_document_path) as f: record.document = f.read() def _set_document(self): for record in self: if not record.document: continue with open(record.get_document_path()) as f: f.write(record.document)
多个字段可以通过同一个方法同时计算,只需在所有字段上使用相同的方法并设置它们::
discount_value = fields.Float(compute='_apply_discount') total = fields.Float(compute='_apply_discount') @api.depends('value', 'discount') def _apply_discount(self): for record in self: # compute actual discount from discount percentage discount = record.value * record.discount record.discount_value = discount record.total = record.value - discount
警告
虽然可以对多个字段使用相同的计算方法,但不建议对逆向方法也这样做。
在计算逆向值时,使用该逆向方法的 所有 字段都会受到保护,这意味着即使它们的值不在缓存中,也无法被计算。
如果访问了这些字段中的任何一个且其值不在缓存中,ORM 将简单地为这些字段返回默认值 False 。这意味着逆向字段(触发逆向方法的那个字段除外)的值可能无法给出正确的值,这可能会破坏逆向方法的预期行为。
自动字段¶
访问日志字段¶
如果启用了 _log_access ,这些字段将自动设置和更新。可以禁用以避免在不需要它们的表上创建或更新这些字段。
默认情况下, _log_access 设置为与 _auto 相同的值
警告
_log_access 必须 在 TransientModel 上启用。
保留字段名称¶
一些字段名称被保留用于预定义的行为,超出了自动化字段的功能。当需要相关行为时,应在模型中定义它们:
- Model.active¶
切换记录的全局可见性,如果将
active设置为False,则记录在大多数搜索和列表中不可见。特殊方法:
- Model.parent_id¶
_parent_name的默认值,用于以树形结构组织记录,并在域中启用child_of和parent_of操作符。
- Model.parent_path¶
当
_parent_store设置为 True 时,用于存储反映_parent_name树结构的值,并优化 搜索域 中的操作符child_of和parent_of。必须使用index=True声明以正确操作。
约束和索引¶
与字段类似,您可以声明 Constraint 、 Index 和 UniqueIndex 。属性名称必须以 _ 开头,以避免与字段名称冲突。
您可以自定义错误消息。它们可以是字符串,其翻译将在内部反射约束表中提供。否则,它们可以是接受 (env, diag) 作为参数的函数,分别表示环境和 psycopg 诊断信息。
Example
class AModel(models.Model):
_name = 'a.model'
_my_check = models.Constraint("CHECK (x > y)", "x > y is not true")
_name_idx = models.Index("(last_name, first_name)")
记录集¶
与模型和记录的交互通过记录集进行,记录集是同一模型记录的有序集合。
警告
与名称所暗示的不同,记录集目前可能包含重复项。这在未来可能会改变。
模型上定义的方法在记录集上执行,其 self 是一个记录集::
class AModel(models.Model):
_name = 'a.model'
def a_method(self):
# self can be anything between 0 records and all records in the
# database
self.do_operation()
迭代记录集将生成 单个记录 的新集合(“单例”),就像迭代 Python 字符串会生成单个字符的字符串一样::
def do_operation(self):
print(self) # => a.model(1, 2, 3, 4, 5)
for record in self:
print(record) # => a.model(1), then a.model(2), then a.model(3), ...
字段访问¶
记录集提供了一个“活动记录”接口:模型字段可以直接作为属性从记录中读取和写入。
注解
当访问可能包含多个记录的记录集上的非关系字段时,请使用 mapped() ::
total_qty = sum(self.mapped('qty'))
字段值也可以像字典项一样访问,这比用于动态字段名称的 getattr() 更优雅且更安全。设置字段值会触发数据库更新::
>>> record.name
Example Name
>>> record.company_id.name
Company Name
>>> record.name = "Bob"
>>> field = "name"
>>> record[field]
Bob
警告
尝试在多个记录上读取字段会引发非关系字段的错误。
访问关系字段( Many2one 、 One2many 、 Many2many ) 始终 返回一个记录集,如果字段未设置,则返回空记录集。
记录缓存与预取¶
Odoo 为记录的字段维护了一个缓存,因此并非每次字段访问都会发出数据库请求,否则会对性能造成严重影响。以下示例仅对第一条语句查询数据库::
record.name # first access reads value from database
record.name # second access gets value from cache
为了避免一次读取一条记录的一个字段,Odoo 预取 记录和字段,遵循一些启发式方法以获得良好的性能。一旦需要读取某个字段,ORM 实际上会在更大的记录集上读取该字段,并将返回的值存储在缓存中以供后续使用。预取的记录集通常是通过迭代获取记录的记录集。此外,所有简单的存储字段(布尔值、整数、浮点数、字符、文本、日期、日期时间、选择项、多对一)都会一起提取;它们对应于模型表的列,并在同一查询中高效提取。
考虑以下示例,其中 partners 是一个包含 1000 条记录的记录集。如果不进行预取,循环将向数据库发出 2000 次查询。而通过预取,仅发出一次查询::
for partner in partners:
print partner.name # first pass prefetches 'name' and 'lang'
# (and other fields) on all 'partners'
print partner.lang
预取也适用于 次级记录 :当读取关系字段时,其值(即记录)会被订阅以供未来的预取使用。访问其中一个次级记录时,会预取来自同一模型的所有次级记录。这使得以下示例仅生成两个查询,一个用于合作伙伴,另一个用于国家::
countries = set()
for partner in partners:
country = partner.country_id # first pass prefetches all partners
countries.add(country.name) # first pass prefetches all countries
参见
方法 search_fetch() 和 fetch() 可用于填充记录缓存,通常是在预取机制无法良好工作的情况下使用。
方法装饰器¶
- odoo.api.autovacuum(method: C) C[源代码]¶
装饰一个方法,使其被每日清理定时任务(模型
ir.autovacuum)调用。这通常用于类似垃圾回收的任务,而无需专门的定时任务。返回值可以是一个元组 (done, remaining),其含义与
_commit_progress()中的类似。
- odoo.api.constrains(*args) Decorator[源代码]¶
装饰一个约束检查器。
每个参数必须是用于检查的字段名称::
@api.constrains('name', 'description') def _check_description(self): for record in self: if record.name == record.description: raise ValidationError("Fields name and description must be different")
在命名字段之一被修改的记录上调用。
如果验证失败,应抛出
ValidationError。警告
@constrains仅支持简单字段名,点号分隔的名称(如关系字段的字段,例如partner_id.customer)不受支持且将被忽略。@constrains仅在装饰方法中声明的字段包含在create或write调用中时触发。这意味着视图中不存在的字段不会在记录创建期间触发调用。需要重写create方法以确保约束始终被触发(例如测试值的缺失)。也可以传递单个函数作为参数。在这种情况下,字段名称是通过使用模型实例调用该函数来提供的。
- odoo.api.depends(*args) Decorator[源代码]¶
返回一个装饰器,指定“计算”方法(针对新式函数字段)的字段依赖项。每个参数必须是一个由点号分隔的字段名称字符串::
pname = fields.Char(compute='_compute_pname') @api.depends('partner_id.name', 'partner_id.is_company') def _compute_pname(self): for record in self: if record.partner_id.is_company: record.pname = (record.partner_id.name or "").upper() else: record.pname = record.partner_id.name
也可以传递单个函数作为参数。在这种情况下,依赖项是通过使用字段的模型调用该函数来提供的。
- odoo.api.depends_context(*args: str) Decorator[源代码]¶
返回一个装饰器,用于指定非存储的“计算”方法的上下文依赖项。每个参数是上下文字典中的键:
price = fields.Float(compute='_compute_product_price') @api.depends_context('pricelist') def _compute_product_price(self): for product in self: if product.env.context.get('pricelist'): pricelist = self.env['product.pricelist'].browse(product.env.context['pricelist']) else: pricelist = self.env['product.pricelist'].get_default_pricelist() product.price = pricelist._get_products_price(product).get(product.id, 0.0)
所有依赖项必须是可哈希的。以下键具有特殊支持:
- odoo.api.model(method: C) C[源代码]¶
装饰一种记录风格的方法,其中
self是一个记录集,但其内容并不重要,只有模型相关。例如:@api.model def method(self, args): ...
- odoo.api.model_create_multi(method: Callable[[T, list[ValuesType]], T]) Callable[[T, list[ValuesType] | ValuesType], T][源代码]¶
装饰一个接受字典列表并创建多条记录的方法。该方法可以使用单个字典或字典列表调用:
record = model.create(vals) records = model.create([vals, ...])
- odoo.api.onchange(*args: str) Decorator[源代码]¶
返回一个装饰器,用于装饰给定字段的 onchange 方法。
在字段出现的表单视图中,当给定字段之一被修改时,将调用该方法。该方法会在一个伪记录上调用,该伪记录包含表单中的值。对该记录的字段赋值会自动发送回客户端。
每个参数必须是字段名称::
@api.onchange('partner_id') def _onchange_partner(self): self.message = "Dear %s" % (self.partner_id.name or "")
return { 'warning': {'title': "Warning", 'message': "What is this?", 'type': 'notification'}, }
如果类型设置为通知,则警告将以通知形式显示。否则,默认情况下将以对话框形式显示。
警告
@onchange仅支持简单字段名称,点号分隔的名称(如关系字段的字段,例如partner_id.tz)不受支持且将被忽略。危险
由于
@onchange返回的是伪记录的记录集,在上述记录集上调用任何 CRUD 方法(如create()、read()、write()、unlink())的行为是未定义的,因为它们可能尚未存在于数据库中。相反,只需像上面示例所示设置记录的字段,或者调用
update()方法。警告
one2many或many2many字段无法通过 onchange 修改自身。这是 Web 客户端的限制 - 参见 #2693 。
- odoo.api.ondelete(*, at_uninstall: bool) Decorator[源代码]¶
标记一个方法以便在
unlink()期间执行。此装饰器的目标是,如果从业务角度来看删除某些记录没有意义,则允许在删除记录时出现客户端错误。例如,用户不应能够删除已验证的销售订单。
虽然可以通过简单地覆盖模型上的
unlink方法来实现这一点,但它有一个缺点,即与模块卸载不兼容。在卸载模块时,覆盖可能会引发用户错误,但我们不应该关心,因为模块正在被卸载,因此与模块相关的 所有 记录都应该被删除。这意味着通过覆盖
unlink,有很大可能某些表/记录会作为卸载模块的残留数据保留下来。这会使数据库处于不一致状态。此外,如果模块在该数据库上重新安装,则可能存在冲突风险。使用
@ondelete装饰的方法应在满足某些条件时抛出错误,并且按照惯例,方法应命名为_unlink_if_<条件>或_unlink_except_<非条件>。@api.ondelete(at_uninstall=False) def _unlink_if_user_inactive(self): if any(user.active for user in self): raise UserError("Can't delete an active user!") # same as above but with _unlink_except_* as method name @api.ondelete(at_uninstall=False) def _unlink_except_active_user(self): if any(user.active for user in self): raise UserError("Can't delete an active user!")
- 参数
at_uninstall (bool) – 当实现所述方法的模块正在被卸载时,是否应调用被装饰的方法。几乎总是应为
False,以便模块卸载不会触发这些错误。
危险
仅当您实现的检查在卸载模块时也适用时,参数
at_uninstall才应设置为True。例如,在卸载
sale时,删除已验证的销售订单并不重要,因为与sale相关的所有数据都应该被删除。在这种情况下,at_uninstall应设置为False。然而,如果没有安装其他语言,则阻止删除默认语言是有意义的,因为删除默认语言会破坏许多基本行为。在这种情况下,
at_uninstall应设置为True。
环境¶
- class odoo.api.Environment(cr: odoo.sql_db.BaseCursor, uid: int, context: dict, su: bool = False)[源代码]¶
环境存储了 ORM 使用的各种上下文数据:
cr:当前数据库游标(用于数据库查询);uid:当前用户 ID(用于访问权限检查);context:当前上下文字典(任意元数据);su:是否处于超级用户模式。
它通过实现从模型名称到模型的映射来提供对注册表的访问。它还包含一个记录缓存和一个用于管理重新计算的数据结构。
>>> records.env
<Environment object ...>
>>> records.env.uid
3
>>> records.env.user
res.user(3)
>>> records.env.cr
<Cursor object ...>
当从另一个记录集创建记录集时,环境会被继承。环境可用于获取另一个模型的空记录集,并查询该模型:
>>> self.env['res.partner']
res.partner()
>>> self.env['res.partner'].search([('is_company', '=', True), ('customer', '=', True)])
res.partner(7, 18, 12, 14, 17, 19, 8, 31, 26, 16, 13, 20, 30, 22, 29, 15, 23, 28, 74)
一些惰性属性可用于访问环境(上下文)数据:
- Environment.lang¶
返回当前语言代码。
- Environment.user¶
返回当前用户(作为实例)。
- 返回
当前用户 - 使用 sudo
- 返回类型
res.users 记录
- Environment.company¶
返回当前公司(作为实例)。
如果未在上下文中指定(
allowed_company_ids),则回退到当前用户的主要公司。- 引发
AccessError –
allowed_company_ids上下文键内容无效或未经授权。- 返回
当前公司(默认值为
self.user.company_id),使用当前环境。- 返回类型
res.company 记录
警告
在 sudo 模式下未应用健全性检查!在 sudo 模式下,用户可以访问任何公司,即使不在其允许的公司范围内。
这允许触发跨公司的修改,即使当前用户无法访问目标公司。
- Environment.companies¶
返回用户启用的公司记录集。
如果未在上下文中指定(
allowed_company_ids),则回退到当前用户的公司。- 引发
AccessError –
allowed_company_ids上下文键内容无效或未经授权。- 返回
当前公司(默认值为
self.user.company_ids),使用当前环境。- 返回类型
res.company 记录集
警告
在 sudo 模式下未应用健全性检查!在 sudo 模式下,用户可以访问任何公司,即使不在其允许的公司范围内。
这允许触发跨公司的修改,即使当前用户无法访问目标公司。
有用的环境方法¶
- Environment.ref(xml_id: str, raise_if_not_found: Literal[True] = True) BaseModel[源代码]¶
- Environment.ref(xml_id: str, raise_if_not_found: Literal[False]) BaseModel | None
返回与给定
xml_id对应的记录。- 参数
- 返回
找到的记录或 None
- 引发
ValueError – 如果未找到记录且
raise_if_not_found为 True
- Environment.execute_query(query: odoo.tools.sql.SQL) list[tuple][源代码]¶
执行给定的查询,获取其结果并将其作为元组列表返回(如果没有结果则返回空列表)。该方法会自动刷新查询元数据中的所有字段。
修改环境¶
- Model.with_context(ctx: dict[str, typing.Any] | None = None, /, **overrides) Self[源代码]¶
返回附加到扩展上下文的新版本记录集。
扩展的上下文可以是提供的
context,其中overrides被合并,也可以是当前上下文,其中overrides被合并,例如:# current context is {'key1': True} r2 = records.with_context({}, key2=True) # -> r2.env.context is {'key2': True} r2 = records.with_context(key2=True) # -> r2.env.context is {'key1': True, 'key2': True}
- Model.with_user(user: BaseModel | IdType) Self[源代码]¶
返回此记录集的新版本,附加到指定用户,处于非超级用户模式,除非
user是超级用户(按照约定,超级用户始终处于超级用户模式)。
SQL 执行¶
环境中的 cr 属性是当前数据库事务的游标,允许直接执行 SQL,无论是因为查询难以用 ORM 表达(例如复杂连接),还是出于性能原因::
self.env.cr.execute("some_sql", params)
警告
执行原始 SQL 会绕过 ORM,从而绕过 Odoo 安全规则。请确保在使用用户输入时对查询进行清理,并在不需要使用 SQL 查询时优先使用 ORM 工具。
构建 SQL 查询的推荐方法是使用包装器对象
- class odoo.tools.SQL(code: str | SQL = '', /, *args, to_flush: Field | Iterable[Field] | None = None, **kwargs)[源代码]¶
一个封装 SQL 代码及其参数的对象,例如:
sql = SQL("UPDATE TABLE foo SET a = %s, b = %s", 'hello', 42) cr.execute(sql)
代码以
%格式字符串给出,支持位置参数(使用%s)或命名参数(使用%(name)s)。参数旨在使用%格式化操作符合并到代码中。请注意,字符%必须始终转义(为%%),即使代码没有参数,如SQL("foo LIKE 'a%%'")。SQL 封装器设计为可组合:参数可以是实际参数,也可以是 SQL 对象本身:
sql = SQL( "UPDATE TABLE %s SET %s", SQL.identifier(tablename), SQL("%s = %s", SQL.identifier(columnname), value), )
合并后的 SQL 代码由
sql.code提供,而相应的合并参数由列表sql.params提供。这允许组合任意数量的 SQL 条件,而无需单独组合它们的参数,后者可能繁琐、容易出错,并且是psycopg2.sql <https://www.psycopg.org/docs/sql.html>的主要缺点。封装器的第二个目的是防止 SQL 注入。确实,如果
code是字符串字面量(而非动态字符串),则使用code创建的 SQL 对象保证是安全的,前提是其参数中的 SQL 对象本身也是安全的。封装器还可能包含一些元数据
to_flush。如果不是None,其值是 SQL 代码所依赖的字段。封装器及其部分的元数据可以通过迭代器sql.to_flush访问。
关于模型,有一个重要的点需要了解:它们不一定会立即执行数据库更新。事实上,出于性能原因,框架会在修改记录后延迟字段的重新计算。某些数据库更新也会被延迟。因此,在查询数据库之前,必须确保数据库包含与查询相关的数据。这一操作称为 刷新 ,它会执行预期的数据库更新。
Example
# make sure that 'partner_id' is up-to-date in database
self.env['model'].flush_model(['partner_id'])
self.env.cr.execute(SQL("SELECT id FROM model WHERE partner_id IN %s", ids))
ids = [row[0] for row in self.env.cr.fetchall()]
在每次 SQL 查询之前,必须刷新该查询所需的数据。刷新分为三个级别,每个级别都有其对应的 API。可以刷新所有内容、某个模型的所有记录,或者某些特定记录。由于延迟更新通常会提高性能,因此我们建议在刷新时尽可能 具体化 。
- Model.flush_model(fnames: Collection[str] | None = None) None[源代码]¶
处理
self模型上的挂起计算和数据库更新。当提供了参数时,该方法保证至少将给定字段刷新到数据库。不过,也可能刷新更多字段。- 参数
fnames – 可选的字段名称可迭代对象以刷新
- Model.flush_recordset(fnames: Collection[str] | None = None) None[源代码]¶
处理记录
self上的挂起计算和数据库更新。当提供参数时,该方法保证至少将self上给定的字段刷新到数据库中。不过,可能会刷新更多字段和记录。- 参数
fnames – 可选的字段名称可迭代对象以刷新
由于模型使用相同的游标,并且 Environment 包含各种缓存,因此在使用原始 SQL 更改 数据库时,必须使这些缓存失效,否则模型的进一步使用可能会变得不一致。在 SQL 中使用 CREATE 、 UPDATE 或 DELETE 时需要清除缓存,而 SELECT (仅读取数据库)则不需要。
Example
# make sure 'state' is up-to-date in database
self.env['model'].flush_model(['state'])
self.env.cr.execute("UPDATE model SET state=%s WHERE state=%s", ['new', 'old'])
# invalidate 'state' from the cache
self.env['model'].invalidate_model(['state'])
与刷新类似,可以使整个缓存、某个模型的所有记录的缓存或特定记录的缓存失效。甚至可以使某些记录或某个模型的所有记录的特定字段失效。由于缓存通常会提高性能,因此我们建议在使缓存失效时尽可能 具体化 。
- Environment.invalidate_all(flush: bool = True) None[源代码]¶
使所有记录的缓存无效。
- 参数
flush – 是否应在失效之前刷新挂起的更新。默认值为
True,这确保了缓存的一致性。除非您知道自己在做什么,否则不要使用此参数。
- Model.invalidate_model(fnames: Collection[str] | None = None, flush: bool = True) None[源代码]¶
当缓存值不再对应于数据库值时,使
self模型的所有记录缓存无效。如果提供了参数,则仅使缓存中的给定字段无效。- 参数
fnames – 可选的字段名称可迭代对象以使其无效
flush – 是否应在失效之前刷新挂起的更新。默认值为
True,这确保了缓存的一致性。除非您知道自己在做什么,否则不要使用此参数。
- Model.invalidate_recordset(fnames: Collection[str] | None = None, flush: bool = True) None[源代码]¶
当缓存值不再对应于数据库值时,使
self中的记录缓存无效。如果提供了参数,则仅使缓存中的self上的给定字段无效。- 参数
fnames – 可选的字段名称可迭代对象以使其无效
flush – 是否应在失效之前刷新挂起的更新。默认值为
True,这确保了缓存的一致性。除非您知道自己在做什么,否则不要使用此参数。
上述方法使缓存和数据库保持一致。然而,如果数据库中计算字段的依赖项已被修改,则需要通知模型以重新计算这些字段。框架唯一需要知道的是 哪些 记录的 哪些 字段发生了变化。
Example
# make sure 'state' is up-to-date in database
self.env['model'].flush_model(['state'])
# use the RETURNING clause to retrieve which rows have changed
self.env.cr.execute("UPDATE model SET state=%s WHERE state=%s RETURNING id", ['new', 'old'])
ids = [row[0] for row in self.env.cr.fetchall()]
# invalidate the cache, and notify the update to the framework
records = self.env['model'].browse(ids)
records.invalidate_recordset(['state'])
records.modified(['state'])
需要确定哪些记录已被修改。有许多方法可以做到这一点,可能涉及额外的 SQL 查询。在上面的示例中,我们利用 PostgreSQL 的 RETURNING 子句来检索信息,而无需额外查询。在通过失效使缓存一致后,调用修改记录的 modified 方法,并传入已更新的字段。
常见的 ORM 方法¶
创建/更新¶
- Model.create(vals_list: list[ValuesType]) Self[源代码]¶
为模型创建新记录。
新记录使用来自字典列表
vals_list的值进行初始化,并在必要时使用default_get()的值。- 参数
vals_list –
模型字段的值,作为字典列表::
[{'field_name': field_value, ...}, ...]
为了向后兼容,
vals_list可能是一个字典。它被视为单例列表[vals],并返回一条记录。详情请参见
write()- 返回
创建的记录
- 引发
AccessError – 如果当前用户不允许创建指定模型的记录
ValidationError – 如果用户尝试为选择字段输入无效值
ValueError – 如果创建值中指定的字段名称不存在。
UserError – 如果操作会导致对象层次结构中出现循环(例如,将对象设置为其自身的父对象)
- Model.copy(default: ValuesType | None = None) Self[源代码]¶
复制记录
self并使用默认值更新它。- 参数
default – 覆盖复制记录的原始值的字段值字典,例如:
{'field_name': overridden_value, ...}- 返回
新记录
- Model.default_get(fields: Sequence[str]) ValuesType[源代码]¶
返回
fields_list中字段的默认值。默认值由上下文、用户默认值、用户回退值以及模型本身决定。- 参数
fields – 请求默认值的字段名称
- 返回
一个字典,将字段名称映射到它们的默认值(如果它们有默认值)。
注解
未请求的默认值不会被考虑,无需为不在
fields_list中的字段返回值。
- Model.name_create(name: str) Union[tuple[int, str], Literal[False]][源代码]¶
通过调用
create()创建一条新记录,仅提供显示名称作为值。新记录将使用适用于此模型的任何默认值或通过上下文提供的值进行初始化。
create()的常规行为适用。- 参数
name – 要创建的记录的显示名称
- 返回
创建记录的 (id, 显示名称) 对值
- Model.write(vals: ValuesType) typing.Literal[True][源代码]¶
使用提供的值更新
self中的所有记录。- 参数
vals – 要更新的字段及其设置的值
- 引发
AccessError – 如果用户不允许修改指定的记录/字段
ValidationError – 如果为选择字段指定了无效值
UserError – 如果操作会导致对象层次结构中出现循环(例如,将对象设置为其自身的父对象)
对于
Many2one,值应为要设置的记录的数据库标识符。对于
One2many或Many2many关系字段,预期值是一个包含Command的列表,用于操作关系。共有 7 条命令:create()、update()、delete()、unlink()、link()、clear()和set()。对于
Date和~odoo.fields.Datetime,值应为日期(时间)或字符串。警告
如果为日期(时间)字段提供了字符串,则必须仅为 UTC 格式,并符合
odoo.tools.misc.DEFAULT_SERVER_DATE_FORMAT和odoo.tools.misc.DEFAULT_SERVER_DATETIME_FORMAT的格式。其他非关系字段使用字符串作为值。
搜索/读取¶
- Model.browse(ids: int | typing.Iterable[IdType] = ()) Self[源代码]¶
在当前环境中返回作为参数提供的 id 的记录集。
self.browse([7, 18, 12]) res.partner(7, 18, 12)
- Model.search(domain: DomainType, offset: int = 0, limit: int | None = None, order: str | None = None) Self[源代码]¶
搜索满足给定
domain的记录,详见 search domain 。- 参数
domain – 搜索域 。使用空列表以匹配所有记录。
offset – 忽略的结果数量(默认:无)
limit – 返回的最大记录数(默认:全部)
order – 排序字符串
- 返回
至多
limit条符合搜索条件的记录- 引发
AccessError – 如果用户无权访问请求的信息
这是一个高级方法,不应被覆盖。其实际实现由方法
_search()完成。
- Model.search_count(domain: DomainType, limit: int | None = None) int[源代码]¶
返回当前模型中匹配 提供的域 的记录数。
- 参数
domain – 搜索域 。使用空列表以匹配所有记录。
limit – 要计数的最大记录数(上限)(默认:全部)
这是一个高级方法,不应被覆盖。其实际实现由方法
_search()完成。
- Model.search_fetch(domain: DomainType, field_names: Sequence[str] | None = None, offset: int = 0, limit: int | None = None, order: str | None = None) Self[源代码]¶
搜索满足给定
domain搜索域 的记录,并将指定字段提取到缓存中。此方法类似于search()和fetch()的组合,但以最少的 SQL 查询完成两项任务。- 参数
domain – 搜索域 。使用空列表以匹配所有记录。
field_names – 要获取的字段名称集合,或
None表示所有标记为prefetch=True的可访问字段offset – 忽略的结果数量(默认:无)
limit – 返回的最大记录数(默认:全部)
order – 排序字符串
- 返回
至多
limit条符合搜索条件的记录- 引发
AccessError – 如果用户无权访问请求的信息
- Model.name_search(name: str = '', domain: DomainType | None = None, operator: str = 'ilike', limit: int = 100) list[tuple[int, str]][源代码]¶
搜索显示名称与给定
name模式在给定operator下匹配的记录,同时匹配可选的搜索域(domain)。例如,用于根据关系字段的部分值提供建议。通常应表现为
display_name的反向操作,但不保证始终如此。此方法等同于调用基于
display_name的search(),并在结果搜索中映射 id 和 display_name。- 参数
name – 要匹配的名称模式
domain – 搜索域(语法参见
search()),指定进一步的限制operator – domain operator for matching
name, such as'like'or'='.limit – 要返回的最大记录数
- 返回
所有匹配记录的
(id, 显示名称)对列表。
- Model.fetch(field_names: Collection[str] | None = None) None[源代码]¶
确保
self中记录的给定字段已在内存中,通过从数据库中提取必要的内容。非存储字段大多会被忽略,除非它们有存储依赖项。此方法应被调用以优化代码。- 参数
field_names – 要获取的字段名称集合,或
None表示所有标记为prefetch=True的可访问字段- 引发
AccessError – 如果用户无权访问请求的信息
此方法通过
_search()和_fetch_query()方法实现,不应被覆盖。
- Model.read(fields: Sequence[str] | None = None, load: str = '_classic_read') list[ValuesType][源代码]¶
读取
self中记录的请求字段,并将其值作为字典列表返回。- 参数
fields – 要返回的字段名称(默认为所有字段)
load – 加载模式,目前唯一的选项是设置为
None以避免加载 m2o 字段的display_name
- 返回
一个字典列表,将字段名称映射到其值,每个记录对应一个字典
- 引发
AccessError – 如果用户无权访问请求的信息
ValueError – 如果请求的字段不存在
这是一个高级方法,不应被覆盖。若要修改从数据库读取字段的方式,请参阅方法
_fetch_query()和_read_format()。
- Model._read_group(domain: DomainType, groupby: Sequence[str] = (), aggregates: Sequence[str] = (), having: DomainType = (), offset: int = 0, limit: int | None = None, order: str | None = None) list[tuple][源代码]¶
获取由
groupby字段分组并按domain过滤记录的aggregates指定的字段聚合。- 参数
domain – 搜索域 。使用空列表以匹配所有记录。
groupby – 记录将按其分组的 groupby 描述列表。groupby 描述可以是一个字段(然后按该字段分组)或一个字符串
'field:granularity'。目前唯一支持的粒度是'day'、'week'、'month'、'quarter'或'year',并且它们仅对日期/日期时间字段有意义。此外,还支持整数日期部分:'year_number'、'quarter_number'、'month_number'、'iso_week_number'、'day_of_year'、'day_of_month'、’day_of_week’、’hour_number’、’minute_number’ 和 ‘second_number’。aggregates – 聚合规范列表。每个元素是
'field:agg'`(使用聚合函数 `'agg'的聚合字段)。可能的聚合函数由 PostgreSQL 提供,包括'count_distinct'`(具有预期含义)和 `'recordset'`(类似于 `'array_agg'并转换为记录集)。having – 一个域,其中有效的“字段”是聚合字段。
offset – 可选的要跳过的组数
limit – 可选的最大返回组数
order – 可选的
order by规范,用于覆盖组的自然排序顺序,另见search()。
- 返回
按顺序包含组值和聚合值(扁平化)的元组列表:
[(groupby_1_value, ... , aggregate_1_value_aggregate, ...), ...]。如果组是关联字段,其值将是一个记录集(具有正确的预取集)。- 引发
AccessError – 如果用户无权访问请求的信息
字段¶
- Model.fields_get(allfields: Collection[str] | None = None, attributes: Collection[str] | None = None) dict[str, ValuesType][源代码]¶
返回每个字段的定义。
返回值是一个字典(以字段名称为索引)的字典集合。_inherits 的字段也包含在内。string、help 和 selection(如果存在)属性会被翻译。
- 参数
allfields – 要记录的字段,如果为空或未提供则记录所有字段。
attributes – 每个字段要返回的属性,如果为空或未提供则返回所有属性。
- 返回
将字段名称映射到属性值字典的字典。
搜索域¶
搜索域是用于过滤和搜索记录集的一阶逻辑谓词。您可以使用逻辑运算符组合字段表达式上的简单条件。
Domain 可用作域的构建器。
# simple condition domains
d1 = Domain('name', '=', 'abc')
d2 = Domain('phone', 'like', '7620')
# combine domains
d3 = d1 & d2 # and
d4 = d1 | d2 # or
d5 = ~d1 # not
# combine and parse multiple domains (any iterable of domains)
Domain.AND([d1, d2, d3, ...])
Domain.OR([d4, d5, ...])
# constants
Domain.TRUE # true domain
Domain.FALSE # false domain
域可以是一个简单条件 (field_expr, operator, value) ,其中:
field_expr(str)当前模型的字段名,或者是通过
Many2one使用点号表示法遍历关系的字段名,例如'street'或'partner_id.country'。如果字段是日期(时间)字段,还可以使用'字段名.粒度'指定日期的一部分。支持的粒度包括'年份'、'季度'、'月份'、'ISO周数'、'星期几'、'月中的天数'、'年中的天数'、'小时数'、'分钟数'、'秒数'。它们均使用整数作为值。
操作符(str)用于将
field_expr与value进行比较的运算符。有效的运算符有:=等于
!=不等于
>大于
>=大于或等于
<小于
<=小于或等于
=?未设置或等于(如果
value为None或False,返回 true,否则行为类似于=)=like(和not =like)将
field_expr与value模式匹配。模式中的下划线_代表(匹配)任何单个字符;百分号%匹配零个或多个字符的任何字符串。like(和not like)将
field_expr与%value%模式匹配。类似于=like,但在匹配前用 ‘%’ 包装valueilike(和not ilike)不区分大小写的
like=ilike(和not =ilike)不区分大小写的
=likein(和not in)等于
value中的任何项目,value应为项目集合child_of是
value记录的子记录(后代)(value可以是一个项目或项目列表)。考虑模型的语义(即遵循由
_parent_name命名的关系字段)。parent_of是
value记录的父记录(祖先)(value可以是一个项目或项目列表)。考虑模型的语义(即遵循由
_parent_name命名的关系字段)。any(和not any)如果通过
field_expr(Many2one、One2many或Many2many)的关系遍历中的任何记录满足提供的域value,则匹配。field_expr应为字段名称。any!(和not any!)类似于
any,但绕过访问检查。
value变量类型,必须可通过
operator与命名字段进行比较。
Example
搜索名称为 ABC 且电话或手机号码包含 7620 的合作伙伴::
Domain('name', '=', 'ABC') & (
Domain('phone', 'ilike', '7620') | Domain('mobile', 'ilike', '7620')
)
搜索至少有一行产品缺货的待开票销售订单::
Domain('invoice_status', '=', 'to invoice') \
& Domain('order_line', 'any', Domain('product_id.qty_available', '<=', 0))
搜索所有出生月份为二月的合作伙伴::
Domain('birthday.month_number', '=', 2)
Domain 可用于将域序列化为由 3 项 tuple (或 list )表示的简单条件的 list 。这种序列化形式有时可能读写更快。域条件可以使用逻辑运算符以 前缀 表示法组合。您可以使用 '&' (AND)、'|' (OR) 组合 2 个域,并使用 '!' (NOT) 否定 1 个域。
# parse a domain (from list to Domain)
domain = Domain([('name', '=', 'abc'), ('phone', 'like', '7620')])
# serialize domain as a list (from Domain to list)
domain_list = list(domain)
# will output:
# ['&', ('name', '=', 'abc'), ('phone', 'like', '7620')]
动态时间值¶
在搜索域的上下文中,对于 日期和日期时间字段 ,值可以是相对于用户时区中 现在 的时刻。提供了一种简单的语言来指定这些日期。它是一个由空格分隔的术语字符串。第一个术语是可选的,是 “today”(午夜)或 “now”。然后,每个术语以 “+”(加)、”-”(减)或 “=”(设置)开头,后跟一个整数和日期单位或小写星期几。
日期单位是:”d”(天)、”w”(周)、”m”(月)、”y”(年)、”H”(小时)、”M”(分钟)、”S”(秒)。对于星期几,”+” 和 “-” 表示下一个和上一个星期几(除非我们已经在该星期几),而 “=” 表示从周一开始的当前周。设置日期时,较低单位(小时、分钟和秒)设置为 0。
Example
Domain('some_date', '<', 'now') # now
Domain('some_date', '<', 'today') # today at midnight
Domain('some_date', '<', '-3d +1H') # now - 3 days + 1 hour
Domain('some_date', '<', '=3H') # today at 3:00:00
Domain('some_date', '<', '=5d') # 5th day of current month at midnight
Domain('some_date', '<', '=1m') # January, same day of month at midnight
Domain('some_date', '>=', '=monday -1w') # Monday of the previous week
删除¶
- Model.unlink() Literal[True][源代码]¶
删除
self中的记录。- 引发
AccessError – 如果用户不允许删除所有给定记录
UserError – 如果该记录是其他记录的默认属性
记录(集)信息¶
- Model.ids¶
返回与
self对应的实际记录 ID 列表。
- odoo.models.env¶
返回给定记录集的环境。
- 类型
- Model.get_metadata() list[ValuesType][源代码]¶
返回有关给定记录的一些元数据。
- 返回
每个请求记录的所有权字典列表,包含以下键: * id:对象 id * create_uid:创建记录的用户 * create_date:记录创建日期 * write_uid:最后更改记录的用户 * write_date:记录最后更改日期 * xmlid:用于引用此记录的 XML ID(如果有),格式为
module.name* xmlids:包含 xmlid 的字典列表,格式为module.name,noupdate 为布尔值 * noupdate:一个布尔值,指示记录是否将被更新
操作¶
记录集是不可变的,但相同模型的集合可以通过各种集合操作组合,返回新的记录集。
record in set返回record(必须是单元素记录集)是否存在于set中。record not in set是其逆操作。set1 <= set2和set1 < set2返回set1是否是set2的子集(分别为非严格和严格)。set1 >= set2和set1 > set2返回set1是否是set2的超集(分别为非严格和严格)。set1 | set2返回两个记录集的并集,即包含两个来源中所有记录的新记录集。set1 & set2返回两个记录集的交集,即仅包含两个来源中共有记录的新记录集。set1 - set2返回一个新记录集,其中仅包含set1中不在set2中的记录。
记录集是可迭代的,因此可以使用常见的 Python 工具进行转换(如 map() 、 sorted() 、 ifilter() 等),但这些工具返回的是 list 或 iterator ,从而无法对其结果调用方法或使用集合操作。
因此,记录集提供了以下操作,尽可能返回记录集本身:
过滤¶
- Model.filtered(func: str | Callable[[Self], bool] | Domain) Self[源代码]¶
返回满足
func的self中的记录。- 参数
func – 一个函数、域或以点分隔的字段名序列
- 返回
满足 func 的记录集,可能为空。
# only keep records whose company is the current user's records.filtered(lambda r: r.company_id == user.company_id) # only keep records whose partner is a company records.filtered("partner_id.is_company")
映射¶
- Model.mapped(func: str | Callable[[Self], T]) list | BaseModel[源代码]¶
对
self中的所有记录应用func,并返回结果作为列表或记录集(如果func返回记录集)。在后一种情况下,返回的记录集顺序是任意的。- 参数
func – 一个函数或以点分隔的字段名称序列
- 返回
如果 func 为假值,则返回 self;否则返回对所有
self记录应用 func 的结果。
# returns a list of summing two fields for each record in the set records.mapped(lambda r: r.field1 + r.field2)
提供的函数可以是一个字符串以获取字段值:
# returns a list of names records.mapped('name') # returns a recordset of partners records.mapped('partner_id') # returns the union of all partner banks, with duplicates removed records.mapped('partner_id.bank_ids')
注解
自 V13 起,支持多关系字段访问,其工作方式类似于映射调用:
records.partner_id # == records.mapped('partner_id')
records.partner_id.bank_ids # == records.mapped('partner_id.bank_ids')
records.partner_id.mapped('name') # == records.mapped('partner_id.name')
排序¶
- Model.sorted(key: Callable[[Self], typing.Any] | str | None = None, reverse: bool = False) Self[源代码]¶
返回按
key排序的记录集self。- 参数
key – 可以是以下之一: * 一个单参数函数,为每条记录返回比较键 * 表示逗号分隔字段名列表的字符串,带有可选的 NULLS (FIRST|LAST) 和 (ASC|DESC) 方向 *
None,在这种情况下记录按照模型的默认顺序排序reverse – if
True, return the result in reverse order
# sort records by name records.sorted(key=lambda r: r.name) # sort records by name in descending order, then by id records.sorted('name DESC, id') # sort records using default order records.sorted()
分组¶
- Model.grouped(key: str | Callable[[Self], T]) dict[typing.Any, Self][源代码]¶
通过
key急切地将self中的记录分组,返回从key的结果到记录集的字典。所有生成的记录集都保证属于同一个预取集。提供了一种便捷的方法来分区现有记录集,无需
_read_group()的开销,但不执行聚合。注解
与
itertools.groupby()不同,它不关心输入顺序,但代价是无法做到惰性处理。
继承与扩展¶
Odoo 提供了三种不同的机制以模块化方式扩展模型:
从现有模型创建一个新模型,在副本中添加新信息,同时保持原始模块不变
就地扩展其他模块中定义的模型,替换之前的版本
将模型的部分字段委托给它所包含的记录
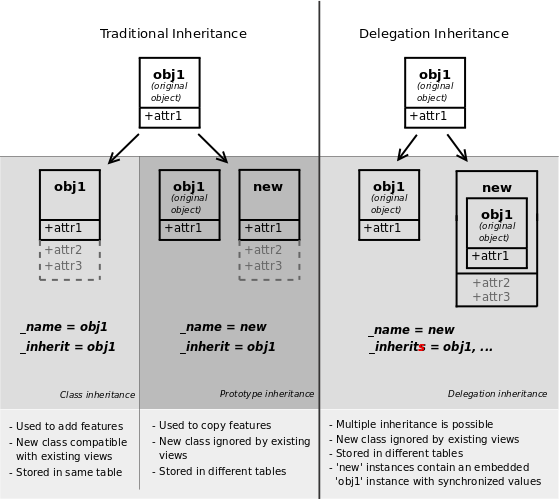
经典继承¶
当同时使用 _inherit 和 _name 属性时,Odoo 使用现有的模型(通过 _inherit 提供)作为基础创建一个新模型。新模型会从其基础模型继承所有字段、方法和元信息(默认值等)。
class Inheritance0(models.Model):
_name = 'inheritance.0'
_description = 'Inheritance Zero'
name = fields.Char()
def call(self):
return self.check("model 0")
def check(self, s):
return "This is {} record {}".format(s, self.name)
class Inheritance1(models.Model):
_name = 'inheritance.1'
_inherit = ['inheritance.0']
_description = 'Inheritance One'
def call(self):
return self.check("model 1")
并使用它们::
a = env['inheritance.0'].create({'name': 'A'})
b = env['inheritance.1'].create({'name': 'B'})
a.call()
b.call()
将产生:
“这是模型 0 的记录 A” “这是模型 1 的记录 B”
第二个模型继承了第一个模型的 check 方法及其 name 字段,但覆盖了 call 方法,这与使用标准的 Python 继承 时的情况类似。
扩展¶
当使用 _inherit 但省略 _name 时,新模型会替换现有模型,实际上是对其进行原地扩展。这对于向现有模型(在其他模块中创建)添加新字段或方法,或对其进行定制或重新配置(例如更改其默认排序顺序)非常有用::
class Extension0(models.Model):
_name = 'extension.0'
_description = 'Extension zero'
name = fields.Char(default="A")
class Extension0(models.Model):
_inherit = ['extension.0']
description = fields.Char(default="Extended")
record = env['extension.0'].create({})
record.read()[0]
将产生::
{'name': "A", 'description': "Extended"}
注解
除非已禁用,否则它还将生成各种 自动字段
委托¶
第三种继承机制提供了更大的灵活性(它可以在运行时更改),但功能较弱:通过使用 _inherits ,模型会将当前模型中未找到的任何字段的查找 委托 给“子”模型。该委托通过父模型上自动设置的 Reference 字段完成。
主要区别在于含义。当使用委托时,模型的关系是 拥有一个 而不是 是一个 ,从而将关系从继承转变为组合::
class Screen(models.Model):
_name = 'delegation.screen'
_description = 'Screen'
size = fields.Float(string='Screen Size in inches')
class Keyboard(models.Model):
_name = 'delegation.keyboard'
_description = 'Keyboard'
layout = fields.Char(string='Layout')
class Laptop(models.Model):
_name = 'delegation.laptop'
_description = 'Laptop'
_inherits = {
'delegation.screen': 'screen_id',
'delegation.keyboard': 'keyboard_id',
}
name = fields.Char(string='Name')
maker = fields.Char(string='Maker')
# a Laptop has a screen
screen_id = fields.Many2one('delegation.screen', required=True, ondelete="cascade")
# a Laptop has a keyboard
keyboard_id = fields.Many2one('delegation.keyboard', required=True, ondelete="cascade")
record = env['delegation.laptop'].create({
'screen_id': env['delegation.screen'].create({'size': 13.0}).id,
'keyboard_id': env['delegation.keyboard'].create({'layout': 'QWERTY'}).id,
})
record.size
record.layout
将导致::
13.0
'QWERTY'
并且可以直接在委托字段上写入::
record.write({'size': 14.0})
警告
当使用委托继承时,方法不会被继承,只有字段会被继承
警告
_inherits的实现或多或少存在问题,如果可以,请尽量避免使用;链式
_inherits基本上未实现,我们无法对最终行为做出任何保证。
字段增量定义¶
字段被定义为模型类上的类属性。如果模型被扩展,也可以通过在子类中重新定义具有相同名称和类型的字段来扩展字段定义。在这种情况下,字段的属性取自父类,并由子类中提供的属性覆盖。
例如,下面的第二个类仅在字段 state 上添加了一个工具提示::
class FirstFoo(models.Model):
state = fields.Selection([...], required=True)
class FirstFoo(models.Model):
_inherit = ['first.foo']
state = fields.Selection(help="Blah blah blah")
class WrongFirstFooClassName(models.Model):
_name = 'first.foo' # force the model name
_inherit = ['first.foo']
state = fields.Selection(help="Blah blah blah")
错误管理¶
Odoo 异常模块定义了一些核心异常类型。
这些类型被 RPC 层理解。任何其他类型的异常冒泡到 RPC 层时都会被视为“服务器错误”。
- exception odoo.exceptions.RedirectWarning(message, action, button_text, additional_context=None)[源代码]¶
带有重定向用户可能性的警告,而不是简单地显示警告消息。